MFT
NTFS는 파일 시스템을 구성하는 모든 요소들을 파일처럼 다룬다. 즉, 파일이 아닌 존재도 파일처럼 저장한다.
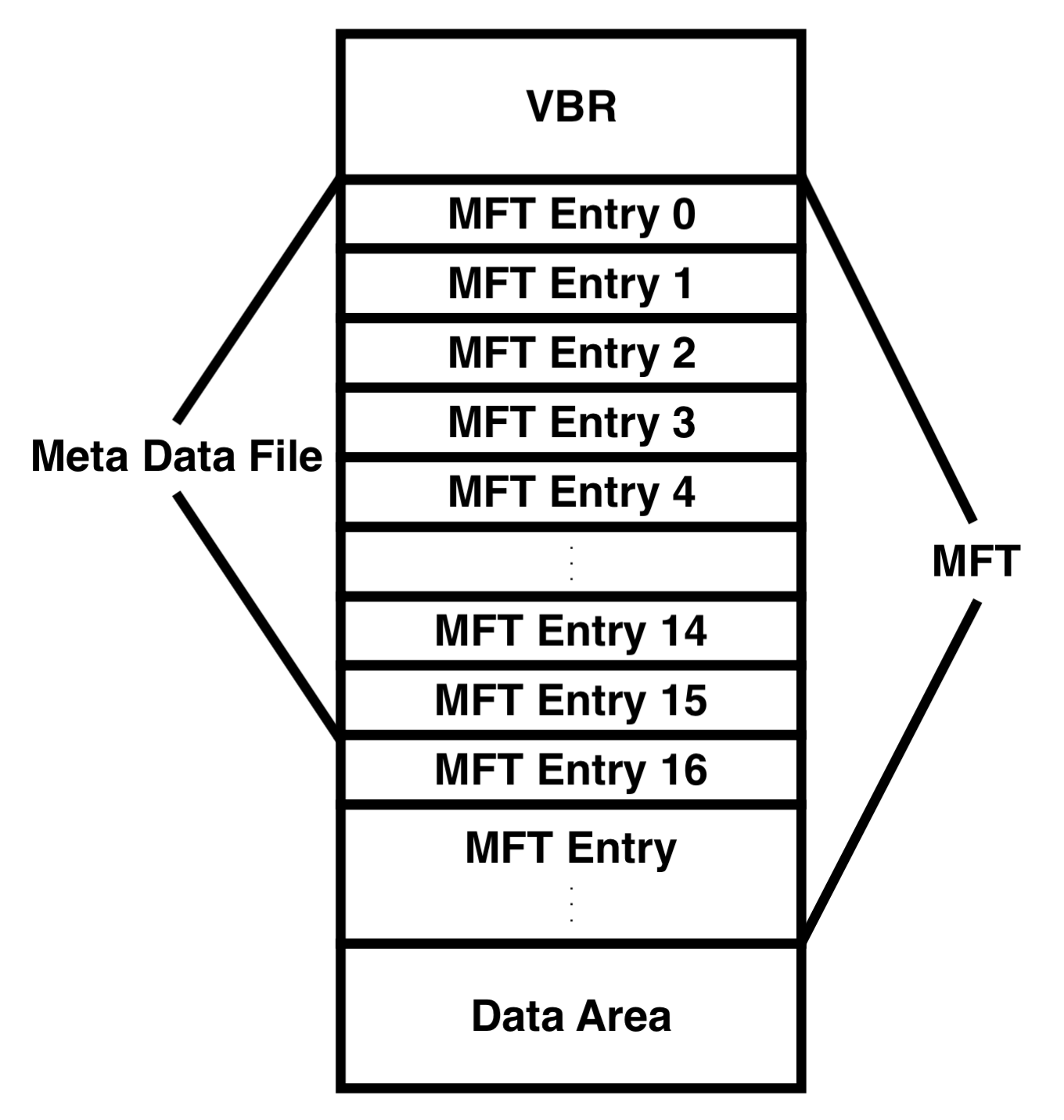
MFT: MFT Entry의 집합으로, 파일 시스템에 저장된 파일의 수에 따라 MFT의 크기가 조절되며, 일반적으로 NTFS 볼륨의 12.5%가 MFT 영역으로 할당된다. 특징으로는, NTFS 파일 시스템을 처음 생성하면 16개의 엔트리(0번부터 15번까지)가 자동으로 생성되며, 이들은 메타 데이터 파일 혹은 시스템 파일이라고 부르며, 특별한 목적을 이유로 예약된 영역이다. 이러한 구조 덕분에 NTFS는 효율적으로 파일들을 관리하고, 필요한 정보에 빠르게 접근할 수 있다.
Start Sector of MFT Area: Start Sector of VBR + (Start Cluster for $MFT x Sector Per Cluster)
해당 파티션에서의 MFT Area는 697,128(128 + (87125 x 8))번 섹터이다.
아래는 NTFS의 구조 중 MFT 영역의 구조를 그림으로 표현한 모습이다.
MFT Entry의 종류인 Metadata File과 나머지 MFT Entry 중 중요한 MFT Entry의 이름과 역할을 표로 정리해 두었다.

| MFT Entry Number | MFT Entry Name | MFT Entry Information |
| 0 | $MFT | 모든 파일의 MFT Entry 정보 |
| 1 | $MFTMirr | $MFT 파일의 일부 백업 데이터 정보 |
| 2 | $LogFile | Metadata의 트랜잭션 저널 정보 |
| 3 | $Volume | 볼륨의 레이블, 식별자, 버전 정보 |
| 4 | $AttrDef | 속성의 식별자, 이름, 크기 정보 |
| 5 | . | Root Directory 정보 |
| 6 | $Bitmap | Cluster Allocation 정보 |
| 7 | $Boot | 부팅 가능한 볼륨의 경우 → Boot Sector 정보 |
| 8 | $BadClus | Bad Sector를 포함한 Cluster 정보 |
| 9 | $Secure | 파일의 보안, 접근제어 정보 |
| 10 | $Upcase | 모든 유니코드 문자의 대문자 정보 |
| 11 | $Extend | $ObjID, $Quota, $Reparse, $UseJrnl의 추가적인 파일의 데이터 저장을 위한 엔트리 |
| 12 ~ 15 | . | 미래를 위해 예약된 영역 |
| 16 ~ | . | 포맷 후 생성되는 파일의 정보 |
| - | $ObjID | 파일의 고유 ID 정보 |
| - | $Quota | 볼륨 사용량 정보 |
| - | $Reparse | Reparse Point 정보 |
| - | $UseJrnl | 파일, 디렉토리 변경 정보 |
MFT Entry
MFT Entry: NTFS에서 저장된 파일(사실상 모든 데이터)에 대한 일부 데이터 및 메타데이터(위치, 속성, 시간 정보, 이름, 크기 등)를 특별한 형태로 저장하는 Entry이다. 크기는 2 섹터를 차지하며, 보통은 1,024바이트이다.
MFT Entry는 크게 MFT Entry Header, Fixup Array, Attribute, End Marker, Unused Space 영역으로 나뉜다.

1. MFT Entry Header
MFT Entry Header: MFT Entry의 메타 데이터(저장 데이터가 파일인지 디렉터리인지, 또는 손상되었는지 등) 정보를 포함하며, 크기는 48 Byte이다.
아래는 MFT Entry Header의 모습이고, 중요한 Field를 표로 정리해 두었다.

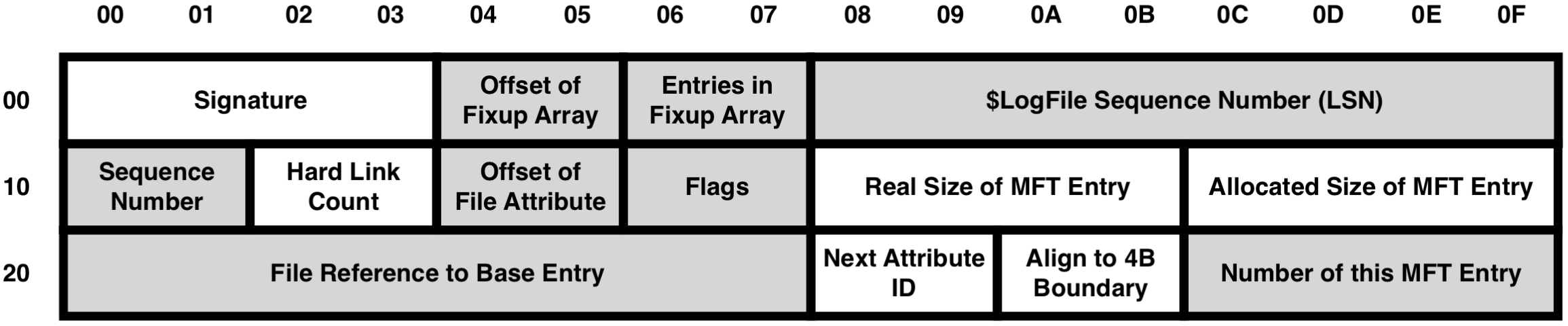
| Size | Information |
| 4 | Signature (FILE) |
| 2 | Offset of Fixup array |
| 2 | Number of Entries in Fixup array (Fixup 배열이 포함하는 항목 수) |
| 8 | $LogFile Sequence Number (LSN) ($LogFile에 존재하는 해당 파일의 트랜잭션 위치 값 MFT Entry가 변경될 때마다 갱신) |
| 2 | Sequence Number (순서 번호로 MFT Entry 생성 후 할당/해제 시마다 1씩 증가) |
| 2 | Hard Link count (해당 MFT Entry에 연결된 하드 링크) |
| 2 | Offset of File attribute (해당 Entry의 첫 번째 속성 주소) |
| 2 | Flags (0x01: 사용중, 0x02: 디렉터리, 0x03, 0x04: 분석 안됨) |
| 4 | Real size of MFT Entry (MFT Entry의 실제 사용 크기) |
| 4 | Allocated size of MFT Entry (MFT Entry의 할당 크기: 1,024 Byte) |
| 8 | File Reference to Base Entry (해당 MFT Entry가 non-base일 경우 자신의 Base Entry의 주소값) |
| 2 | Next attribute ID |
| 2 | Windows XP의 경우 → 존재 |
| 4 | Number of this MFT Entry (MFT Entry Address) (MFT Entry Number) (Record Number) |
1 - 1. Base & Non-Base MFT Entry
MFT Entry Header의 "File Reference to Base Entry" Field에서 값을 확인할 수 있다.
저장하려는 파일의 속성 내용이 많아 MFT Entry에 담을 수 없는 경우 하나 이상의 MFT Entry를 사용하게 된다.
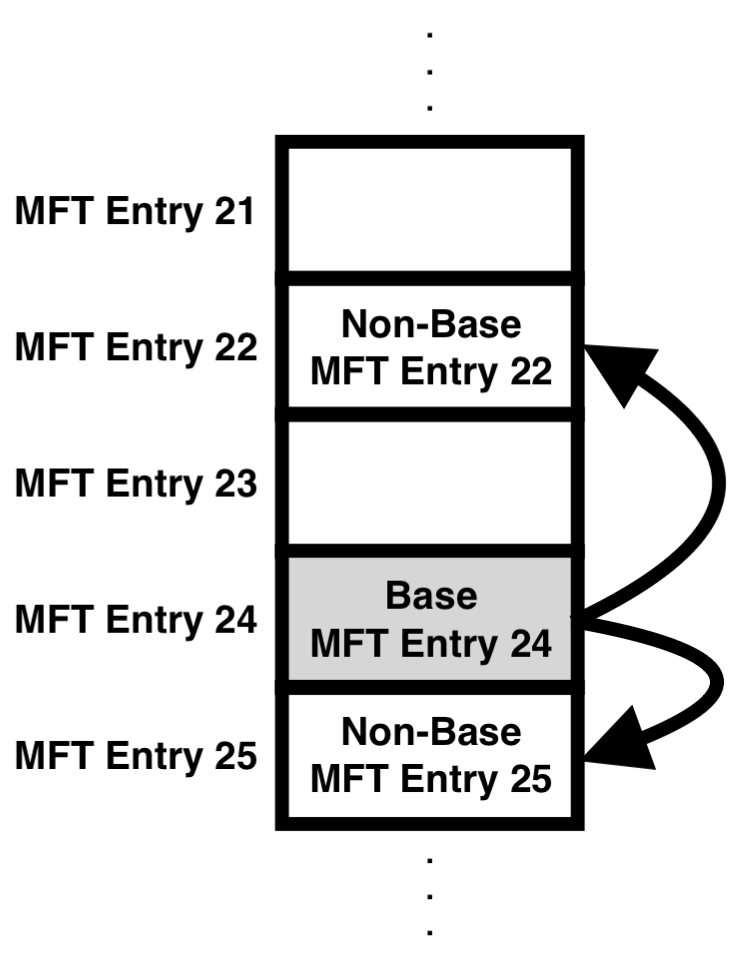
하나의 파일을 저장할 때 여러 개의 MFT Entry를 사용하는 경우 Non-Base MFT Entry는 해당 파일의 첫 MFT Entry를 의미하고, Base MFT Entry는 Non-Base MFT Entry를 제외한 추가로 생성된 MFT Entry를 의미한다.
아래는 하나의 파일을 저장할 때, 속성이 많아 3개의 MFT Entry가 할당된 상태이다. 추가적으로 Base MFT Entry는 24번째 MFT Entry이고, Non-Base MFT Entry는 22, 25번째 MFT Entry이다.
Base MFT Entry의 "File Reference to Base Entry" 값은 "0x00 00 00 00"이고, Non-Base MFT Entry의 "File Reference to Base Entry" 값은 Base MFT Entry의 번째인 "0x18 00 ?? ??"이며, 이때 마지막 바이트는 Base MFT Entry의 Sequence Number 값과 동일하다.
1 - 2. File Reference Address
File Reference Address: 하나의 MFT Entry에서 파일이나 디렉터리를 고유하게 식별하는 데 사용되는 주소로, "Sequence Number(2 Byte) + MFT Entry Address(6 Byte)"의 총 8 Byte크기로 이루어져 있다. Sequence Number와 MFT Entry Address는 MFT Entry Header에서 확인할 수 있다.
Sequence Number: 해당 MFT Entry가 재사용될 때마다 값이 증가한다. 즉, MFT Entry가 새로운 파일이나 디렉터리에 재할당될 때마다, Sequence Number 값이 1씩 증가한다. 단순히 파일이나 디렉터리가 삭제되었을 때 증가하지 않는다.
Sequence Number 증가하는 예시로는 다음과 같다. 파일이나 디렉터리가 삭제되면, 해당 MFT Entry는 재사용을 위해 '가용 상태(free state)'로 표시되며, 이때까지 Sequence Number는 변경되지 않는다. 이후에 NTFS가 다른 파일이나 디렉터리를 이전에 삭제된 파일의 MFT Entry(가용 상태의 MFT Entry)에 재할당하면, Sequence Number가 '1' 증가한다.
MFT Entry Address (MFT Entry Number): 각 파일 또는 디렉터리는 Master File Table(MFT) 내에서 고유한 주소인 MFT Entry Address를 가지며, 이 주소는 파일이나 디렉터리가 MFT 내에서 차지하는 MFT Entry의 번째 수를 나타낸다. $MFT가 0번째이다.
Sequence Number 사용 이유: MFT Entry Address를 재사용하는 서로 다른 파일을 정확하게 구별하고, 이에 따라 올바른 파일에 접근할 수 있게 하여 파일의 무결성과 일관성을 유지하는 중요한 역할을 하기 때문이다.
만약 'test1.txt' 파일이 있을 때, 해당 파일을 삭제한 후 그 위치에 'test2.txt' 파일이 저장되었다고 가정했을 때의 과정은 다음과 같다.
1. 'test1.txt' 파일 생성 및 삭제: 'test1.txt' 파일이 특정 MFT Entry에 할당된다. 이때, 이 MFT Entry는 고유한 'MFT Entry Address'와 초기 'Sequence Number'(0x01)를 가지며, 파일이 삭제되면 해당 MFT Entry는 재사용될 수 있는 가용 상태가 된다. 하지만 이 시점에서는 아직 'Sequence Number'는 변경되지 않는다.
2. 'test2.txt' 파일 저장 및 MFT Entry 재할당: 'test1.txt' 파일이 사용했던 MFT Entry를 'test2.txt' 파일이 재할당 받게 된다. 이때, 'Sequence Number'는 '1'이 증가(0x02)한다. 이제 'test2.txt' 파일의 'File Reference Address'는 이전 파일과 동일한 'MFT Entry Address'를 가지지만, 증가된 'Sequence Number'(0x02)를 포함한다는 차이점이 있다.
3. 파일 식별: NTFS는 특정 파일에 접근할 때, 'File Reference Address'를 확인한다. 'MFT Entry Address'가 같더라도, 'Sequence Number'가 0x02이면 NTFS는 'test1.txt'가 아닌 'test2.txt' 파일로 인식한다.
아래는 File Reference Address의 구조이다.

2. Fixup Array
Fixup Array: NTFS에서 MFT (Master File Table) Entry의 데이터 무결성을 보장하는 데 사용한다. 이 Array는 MFT Entry의 각 섹터의 마지막 2 Byte를 특정 Signature로 값을 대체하고 기존 값을 Array에 나열하여 저장한다. 디스크 상의 오류 또는 데이터 손상을 방지하기 위해, NTFS는 데이터를 디스크에 기록할 때 이 Fixup Array를 사용하여 원래의 섹터 종단 값을 대체하고, 데이터를 읽을 때 원래 값으로 복원하여 데이터 무결성을 검증한다.
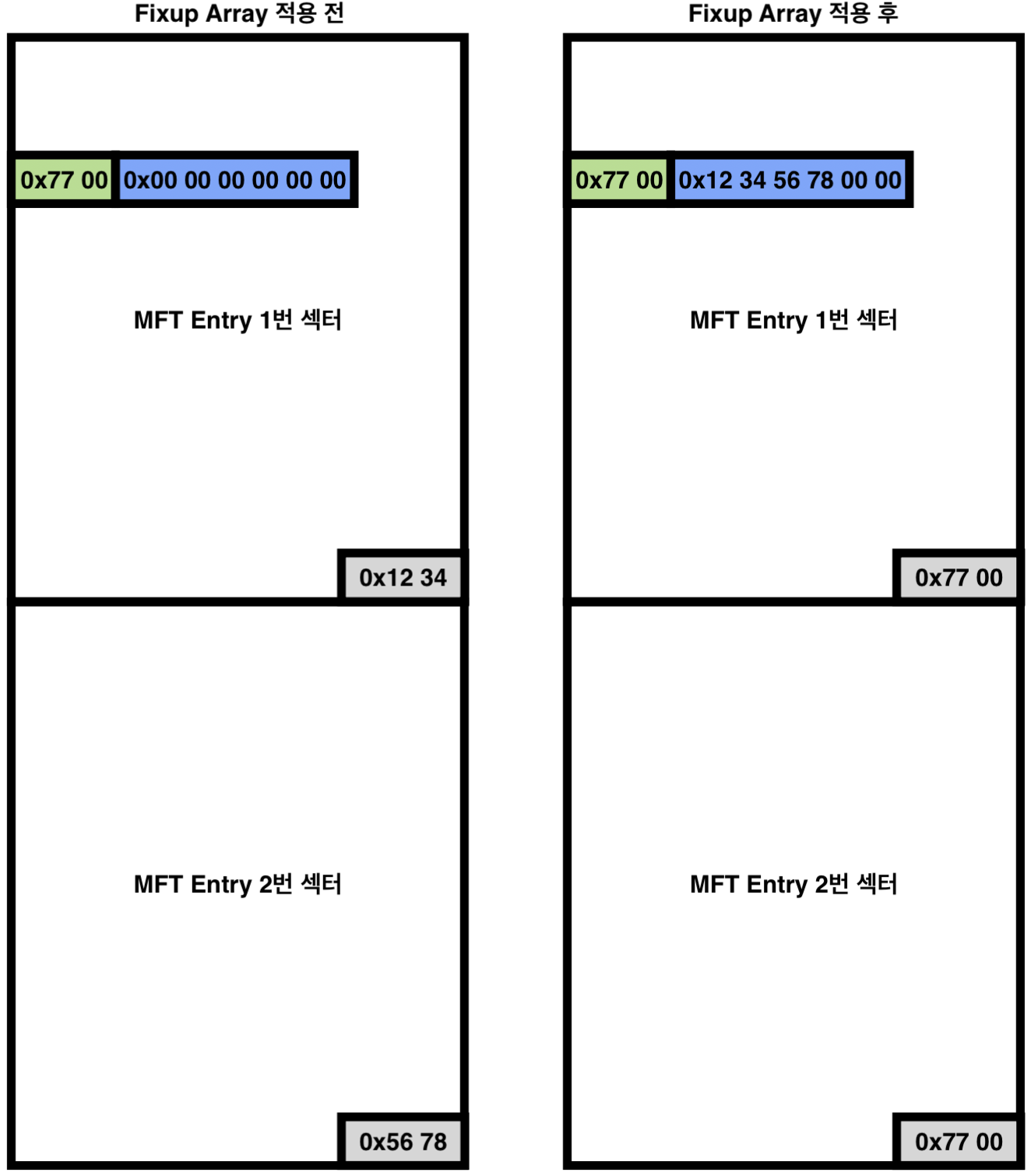
아래는 MFT Entry에서의 Offset of Fixup Array (빨간색), Number of Entries in Fixup Array (빨간색) 값과 Fixup Array의 Signature (초록색) 값과 기존의 마지막 섹터 2 Byte를 백업하여 저장한 Array (파란색) 값이다.
Fixup Array의 크기는 Signature 크기와 Number of Entries in Fixup Array크기의 합으로 결정되지만 Signature는 항상 2 Byte이기 때문에 사실상 Number of Entries in Fixup Array에 따라 결정된다.
해당 경우 Fixup Array의 시작 주소(Offset of Fixup array: 0x30)는 0x30 (48 Byte)이고 Array의 크기(Number of Entries in Fixup array: 0x03)는 0x03 x 2 (6 Byte)이다. 즉, 총 Fixup Array의 크기는 8 Byte이다.

아래는 MFT Entry에 Signature(초록색)와 Fixup Array(파란색)이 존재하며, Fixup Array의 적용 전 (왼쪽), 적용 후 (오른쪽) 모습을 그림으로 표현한 모습이다.
Fixup Array를 적용하면, MFT Entry의 1번 섹터의 마지막 2 Byte (0x12 34)와 MFT Entry의 2번 섹터의 마지막 2 Byte (0x56 78)이 순서대로 Fixup Array에 저장된다. 추가적으로 MFT Entry의 1번 섹터의 마지막 2 Byte와 MFT Entry의 2번 섹터의 마지막 2 Byte에 Signature 값인 "0x77 00"이 저장된다.
3. Attribute
Attribute (Area): Attribute Entry의 집합으로, MFT Entry의 가장 많은 비중을 차지한다.
Attribute Entry: Attribute Header와 Attribue Content로 이루어져 있으며, 파일의 모든 메타데이터 정보와 일부의 경우 파일의 데이터 자체를 포함한다.
아래는 MFT Entry에서 Attribute Area의 구조를 세분화 한 모습이다.
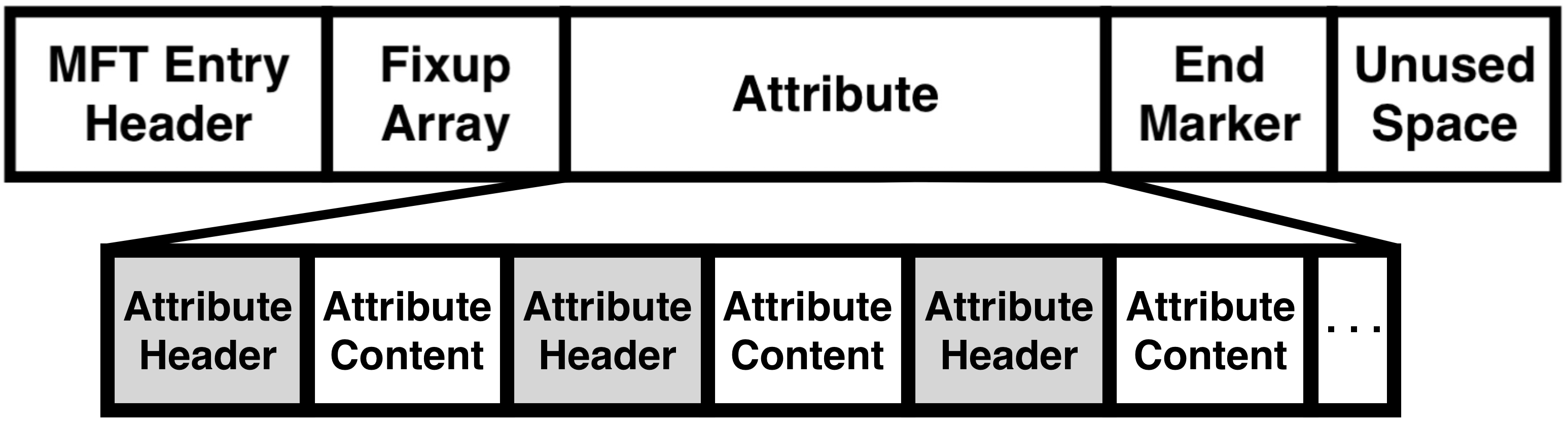
각각의 Attribute Entry는 Attribute의 '파일 크기'에 따라서 Resident 속성과 Non-Resident 속성으로 나뉜다. 여기서 '파일 크기'의 의미는 실제로 저장하려는 '전체 파일의 데이터 크기(ex: text 파일, 이미지, 영상)'가 아니라, Attribute Area에 존재하는 각각의 '하나의 Attribute Entry가 저장하는 데이터 크기'를 의미한다. ('파일 크기'의 의미를 혼동해서는 안 된다.)
NTFS에서 하나의 파일을 저장할 때 하나의 MFT Entry가 생성되고, 이 MFT Entry 내의 Attribute Area에는 여러 개의 Attribute Entry가 생성된다. 이 각각의 Attribute Entry는 독립적으로 Resident Attribute 혹은 Non-Resident Attribute으로 설정될 수 있다.
'파일 크기' < 700 Byte: Resident Attribute
'파일 크기' > 700 Byte: Non-Resident Attribute
Resident Attribute: 주로 크기가 작은 파일에 해당되며, 파일의 크기가 MFT Entry의 할당된 공간에 들어갈 수 있을 정도로 작을 때 이 방식을 사용한다. 파일의 전체 내용이 MFT Entry 내부에 직접 저장된다.
Non-Resident Attribute: 주로 크기가 큰 파일에 해당되며, 파일의 내용이 MFT Entry의 할당된 공간에 포함할 수 없을 정도로 클 때 이 방식을 사용한다. 파일의 전체 내용이 MFT Entry 외부에 저장되며, Attribute Entry에는 해당 데이터가 실제로 저장된 위치에 대한 정보가 포함된다. 추가적으로 $DATA 속성의 경우에는 파일 크기에 따라서 속성이 달라진다.
1. Attribute Header
Attribute Header는 Resident Attribute의 경우와 Non-Resident Attribute의 경우로 총 2가지로 나뉜다. 특이한 점이라면, 공통적으로 갖는 Header 영역으로 Common Attribute Header가 존재한다. 아래와 같은 모습으로 이해하면 된다.
Attribute Header (Resident) = Common Attribute Header + Resident Attribute Header
Attribute Header (Non-Resident) = Common Attribute Header + Non-Resident Attribute Header

1 - 1. Common Attribute Header
Attribute Header에서 Resident Attribute의 경우와 Non-Resident Attribute의 경우에 상관없이 공통으로 갖는 영역으로 크기는 0x10 Byte, 16 Byte이다.
아래의 경우 Attribute Header의 Attribute Type ID(0x10)로 해당 Attribute이 '$STANDARD_INFORMATION'라는 정보와 Attribute Entry의 크기가 0x60이라는 정보를 알 수 있다.

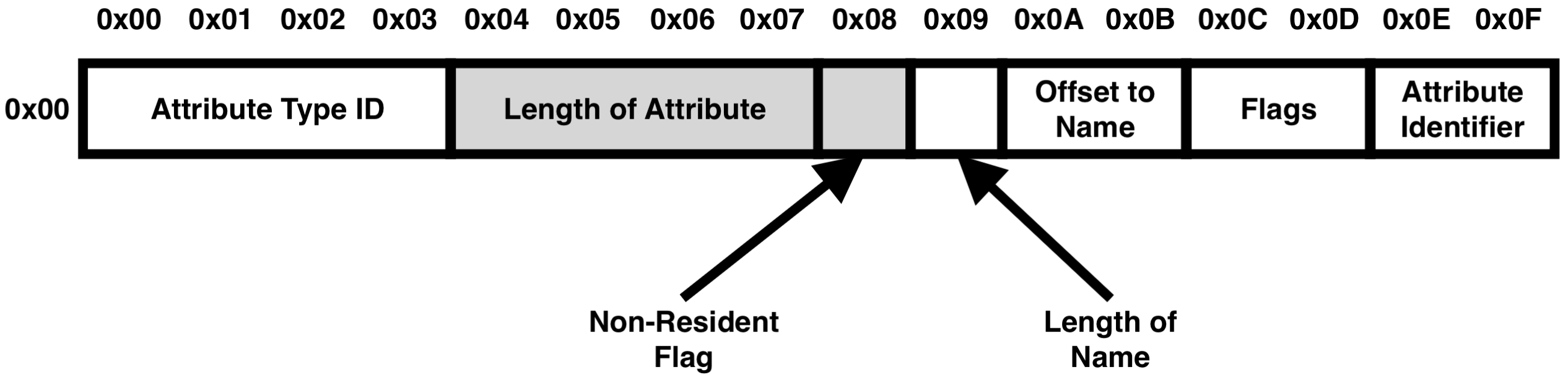
| Size (Byte) | Information |
| 4 | Attribute Type ID (속성 타입 식별값) |
| 4 | Length Of Attribute (속성의 전체 길이(헤더길이 포함)) |
| 1 | Non-Resident Attribute Flag (0x01: Non-Resident Attribute) |
| 1 | Length Of Name (해당 속성의 이름 길이) |
| 2 | Offset to Name (해당 속성 이름이 저장된 곳의 주소) |
| 2 | Flags (0x0001 : 압축 속성) (0x4000 : 암호화 속성) (0x8000: Sparse 속성) |
| 2 | Attribute Identifier (속성의 고유한 식별자로 MFT Entry에 같은 속성이 여러 개일 경우 구별하기 위해 사용) |
1 - 2. Resident Attribute Header
Attribute Header에서 Resident Attribute(초록색)의 경우 Common Attribute Header(빨간색) 다음으로 나오는 영역으로 크기는 8 or 16 Byte이다.

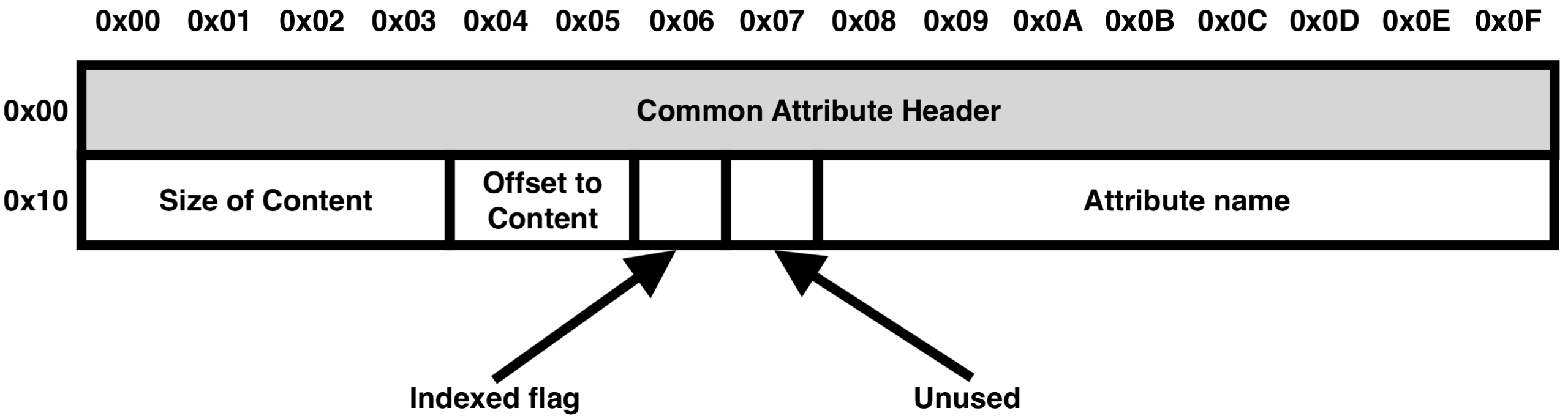
| Size (Byte) | Information |
| 4 | Size of Content (헤더를 제외한 Attribute Entry 크기) |
| 2 | Offset to Content (Attribute Entry의 시작을 기준으로 Attribute Content 시작 주소) |
| 1 | Indexed Flag (0x01: Index 된 상태) |
| 1 | Unused |
| 8 | Attribute name (속성 이름이 있는 경우 → 속성 이름) (속성 이름이 없는 경우 → 존재 X) |
1 - 3. Non-Resident Attribute Header
Attribute Header에서 Non-Resident Attribute Header(초록색)의 경우 Common Attribute Header(빨간색) 다음으로 나오는 영역으로 크기는 0x30 or 0x38 Byte이다.
아래의 경우 Non-Resident Attribute이므로 Common Attribute Header의 Non-Resident Flag 값이 '0x01'이며, Common Attribute Header의 Attribute Size가 0x48이므로 이후에 8 Byte의 Attribute가 존재한다. 'Offset to RunList'의 값이 0x40이므로 0x40 ~ 0x47의 데이터인 이 8 Byte의 데이터는 Non-Resident Attribute Header의 'RunList'이다. 즉, Attribute Name이 존재하지 않는 경우이다.


| Size (Byte) | Information |
| 8 | Start VCN(Virtual Cluster Number) of RunList (Attribute Content이 담긴 runlist의 시작 VCN) (대부분 0x00 00 00 00이다.) |
| 8 | End VCN(Virtual Cluster Number) of RunList (Attribute Content이 담긴 runlist의 끝 VCN) |
| 2 | Offset to RunList (런리스트 시작 주소(헤더에서 시작)) |
| 2 | Compression Unit Size (압축 속성의 경우 → 압축 단위) |
| 4 | Unused |
| 8 | Allocated size of Attribute Content (Attribute Content 저장 시 할당된 클러스터 크기) |
| 8 | Real size of Attribute Content (Attribute Content 실제 크기) |
| 8 | Initialized Size of Attribute Content (Attribute Content 할당된 크기) |
| 8 | Attribute Name (속성 이름이 있는 경우 → 속성 이름) (속성 이름이 없는 경우 → 존재 X) |
1 - 3 - 1. Cluster Runs & RunList
Cluster Run: 데이터 저장 시 클러스터가 연속 혹은 비연속 적으로 할당된 경우 할당된 클러스터의 시작 주소와 크기 정보를 포함하는 데이터이다.
RunList: Cluster Run의 데이터를 효율적으로 표기하는 방식이다.
즉, NTFS는 RunList를 참조하여 Cluster Run 데이터를 추출하고, 추출된 Cluster Run 데이터로 할당된 클러스터에 정상적으로 접근한다. Cluster Run의 시작 주소는 "Attribute Entry의 시작 주소 + Offset of RunList(Non-Resident Attribute Header 참조)"이다.
아래는 Attribute Entry의 모습으로 Common Attribute Header(빨간색), Non-Resident Attribute(초록색), RunList(파란색)의 모습이다.

RunList
RunList는 Byte Size, Run Length, Run Offset의 세 가지 영역으로 나뉜다.
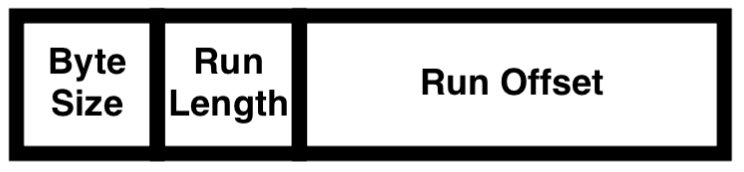
아래의 예시로 RunList를 해석해 보면 다음과 같다.
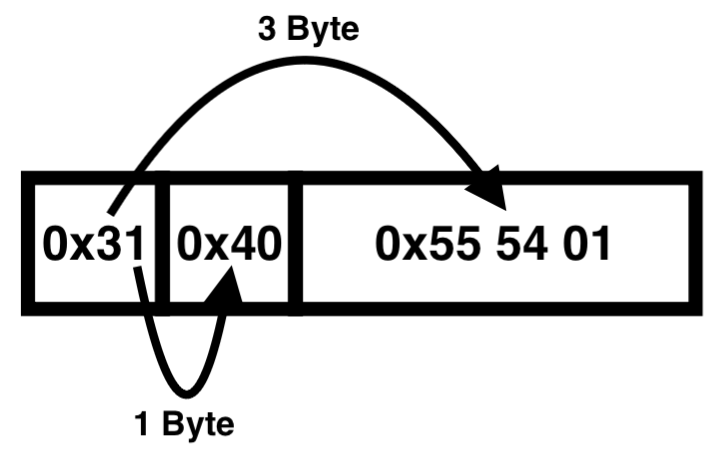
RunList의 값은 0x31 40 55 54 01이고, 항상 첫 1 Byte는 Byte Size 영역으로 예시에서는 '0x31'이다. 여기서 앞자리 '3'과 뒷자리 '1'은 각각 Run Offset과 Run Length의 Byte 크기이다. 즉, Byte Size는 '0x31', Run Length는 '0x40', Run Offset은 '0x55 54 01'가 된다.
Run Length는 파일 저장 시 할당된 클러스터의 수이며, Run Offset은 저장된 파일의 시작 클러스터 주소이다. NTFS는 Run Offset에서 Run Length 만큼의 데이터를 읽는 행위를 통해 해당 Attribute Entry에 저장된 파일에 접근한다. 또한 두 값을 이용해 수동으로 저장된 파일에 접근하거나 카빙이 가능하다. 위의 예시에서는 87,125(0x01 54 55) 번 째 클러스터에서부터 64(0x40) 개의 클러스터가 순차적으로 할당되어 파일이 저장된 경우임을 의미한다.
위의 사례는 파일 저장 시 연속적으로 클러스터가 할당된 경우이다. 아래의 경우는 RunList 내부에 Entry가 2개 있는 경우이다. 이는 비연속적으로 클러스터가 할당되어 파일을 저장한 경우임을 의미한다. 비연속적으로 클러스터가 할당된 경우 RunList 내부에 Entry를 각각 따로 해석하면 된다.
아래는 Attribute Entry의 모습으로 Common Attribute Header(빨간색), Non-Resident Attribute(초록색), RunList(파란색)의 모습이다. Common Attribute Header에서 Attribute Size가 0x50, Non-Resident Attribute Header에서 Offset to RunList가 0x40이라는 점에서 RunList가 0x40 ~ 4F 임을 계산할 수 있다.

위의 경우, RunList는 '0x31 01 54 54 01 31 01 D1 AB FE'이다. 첫 1 Byte는 Byte Size이므로 0x31은 Byte Size이고 위에서 설명한 대로 계산하면, 첫 번째 Entry는 Byte Size는 '0x31', Run Length는 '0x01', Run Offset은 '0x54 54 01'이 된다. 두 번째 Entry도 마찬가지로 계산하면 Byte Size는 '0x31', Run Length는 '0x01', Run Offset은 '0xD1 AB FE'가 된다. 87,124(0x54 54 01) 번 째 클러스터에서 1개의 클러스터를 읽고, 16,690,129(0xD1 AB FE) 번 째 클러스터에서 1개의 클러스터를 순차적으로 접근하여 해당 Attribute Entry에 저장된 파일을 정상적으로 읽을 수 있게 된다.
File Carving
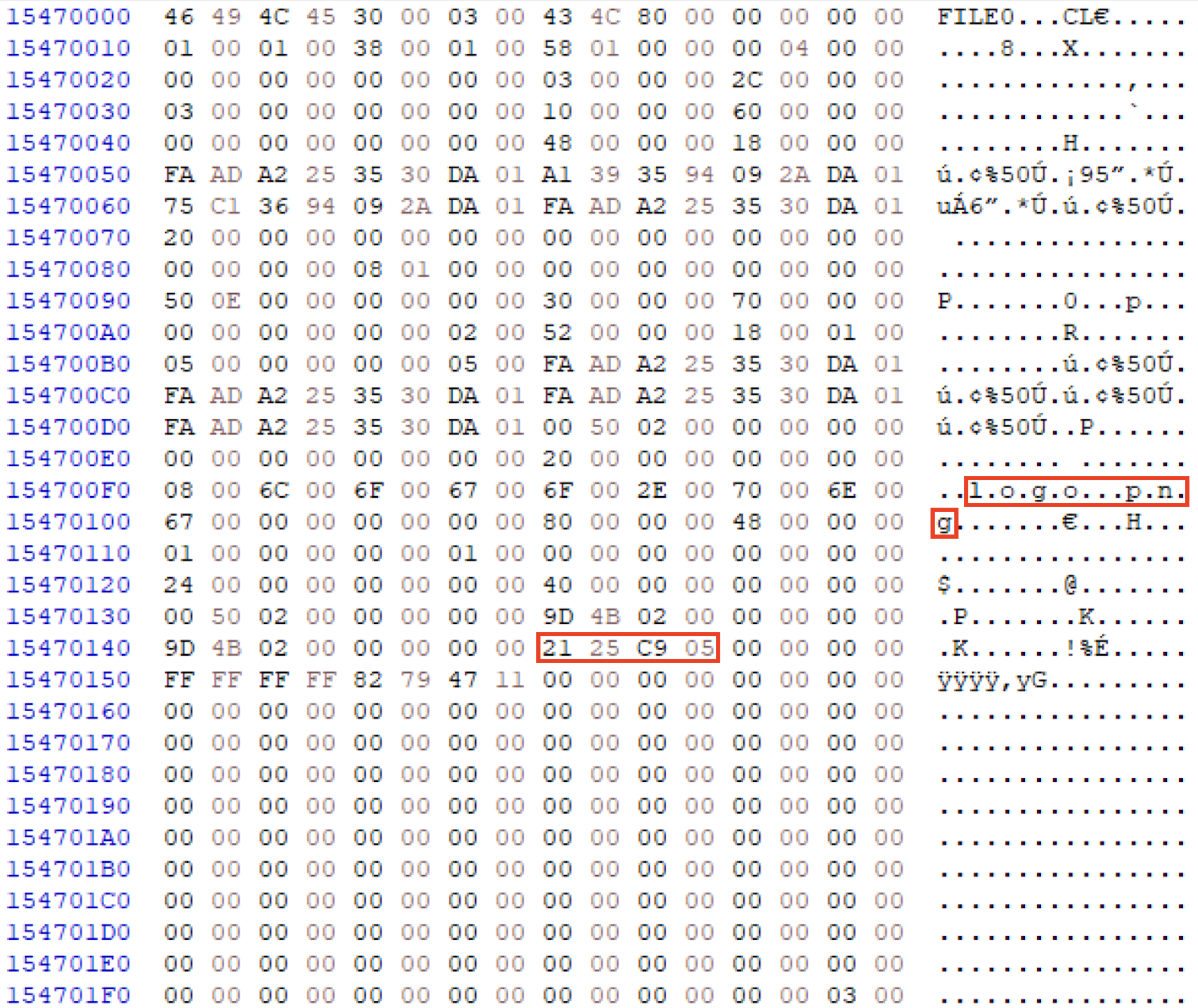
아래는 본 블로그 로고 png 파일(logo.png)을 직접 저장하고, RunList 값을 읽어 수동 카빙 해 본 과정이다. 윈도우자체에서 'logo.png'파일의 속성을 눌러 정보를 확인하면 다음과 같다. 논리 크기는 150,429 Byte이고, 디스크 할당 크기는 151,552 Byte이다. 151,552 Byte의 디스크 할당 크기는 296개의 섹터와 37개의 클러스터를 의미한다.

아래는 logo.png 파일의 MFT Entry이다. RunList(빨간색)가 존재하며, Byte Size는 '0x21', Run Length는 '0x25', Run Offset은 '0xC9 05'가 된다. 파일 카빙은 1,481(0x05 C9) 번 째 클러스터에서 37(0x25) 개의 클러스터를 카빙 하면 된다. 이 말은 11,976(11,848 + 128) 번째 섹터에서 296개의 섹터를 카빙 한다는 의미와 동일하다. 37개의 클러스터가 할당된 모습과, 296개의 섹터를 바이트로 환산하면 151,552(296 x 512) Byte 인 점은 윈도우에서 표시된 값과 정확히 일치한다
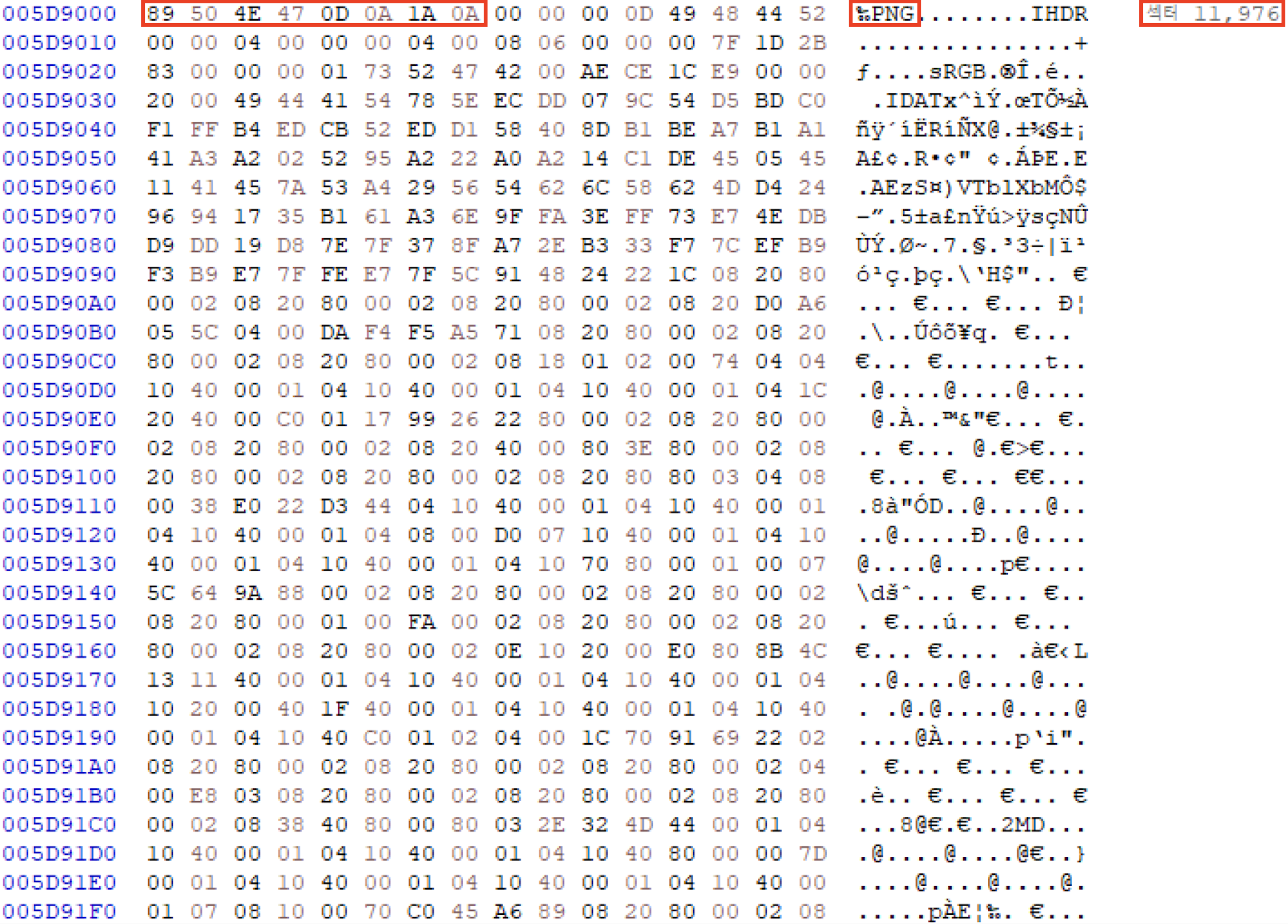
아래는 HxD를 이용해 수동 카빙하는 과정이다.
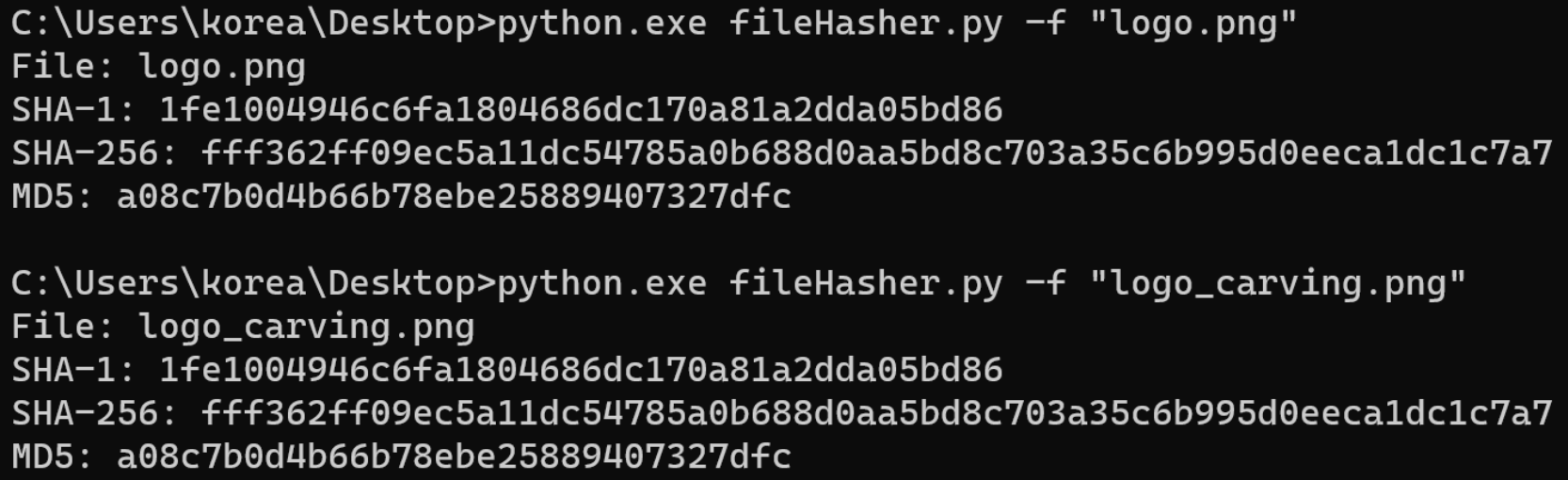
11,976 섹터에서부터 151,552(296 x 512) Byte 만큼을 추출(복사)한다. 11,976 섹터에 png파일의 헤더시그니처가 확인된다.
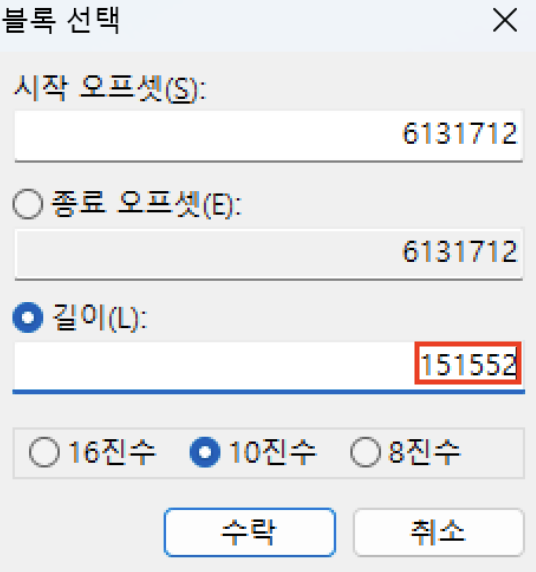
다음으로 추출(복사) 한 데이터를 새로운 파일에 붙여 넣어 저장한다. 단, 파일의 끝 영역까지 정확하게 추출해야한다.
아래는 fileHasher.py라는 도구로 파일의 Hash 값을 출력한 모습이다. 기존의 'logo.png'파일과 카빙의 결과인 'logo_carving.png'파일의 해시값이 일치함을 확인할 수 있다.
LCN, VCN
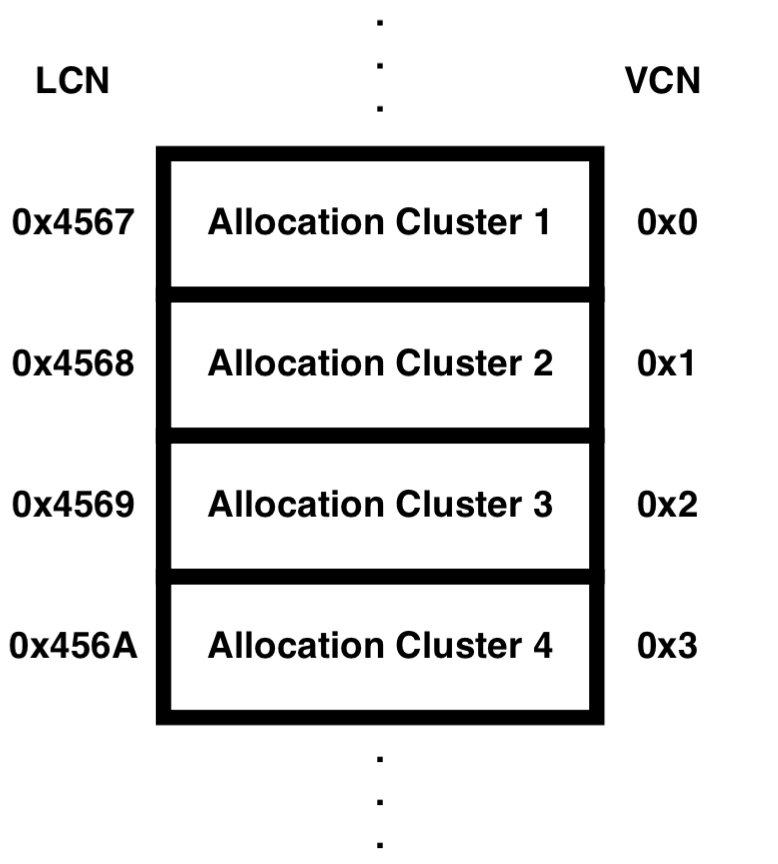
LCN (Logical Cluster Number): 볼륨의 첫 번째 클러스터부터가 0이 되는 순차적인 논리 클러스터 번호이다.
VCN (Virtual Cluster Number): 파일의 첫 번째 클러스터부터가 0이 되는 순차적인 가상 클러스터 번호이다.
Run Offset은 LCN 값이며, 위의 예시에서 첫 번째 Entry가 0번째 VCN에 해당하며, 두 번째 Entry가 1번째 VCN에 해당한다. Non-Resident Attribute Header의 End VCN of RunList가 '2'가 아닌 '1'로 되어있다.
아래는 저장 시 4개의 클러스터가 할당되어야 하는 파일의 저장 상황에서의 LCN과 VCN을 그림으로 표현한 모습이다.
다음 글
[Digital Forensic] NTFS File System "Attribute Content" Analysis